Understanding Clustering Analysis
Basic Concept
- Basic idea: group together similar instances
- Example: 2D point patterns
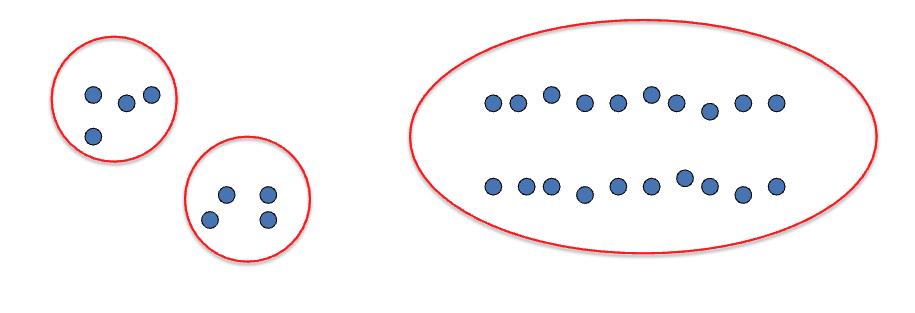

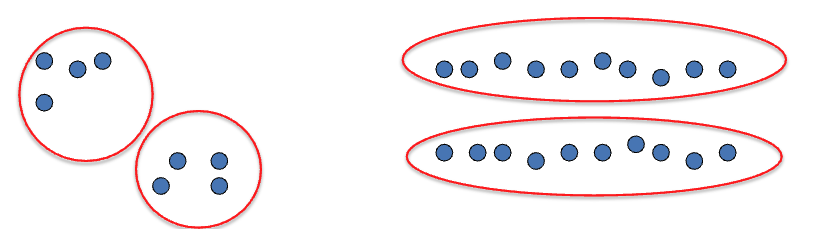
Clustering Algorithms
Two main categories:
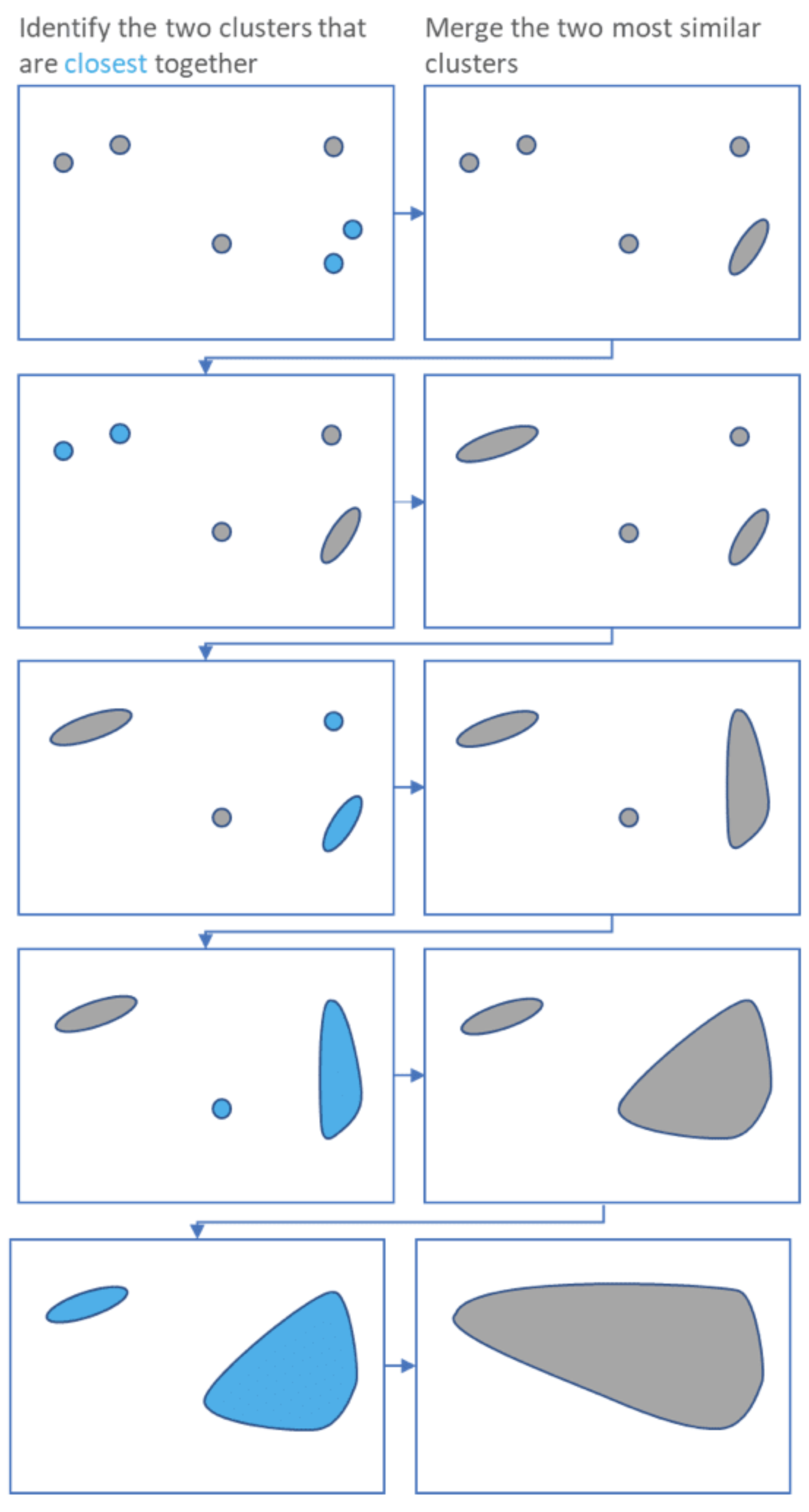
- Hierarchical algorithms
- Bottom-up: agglomerative
- Top-down: divisive
- Partitional algorithms (flat)
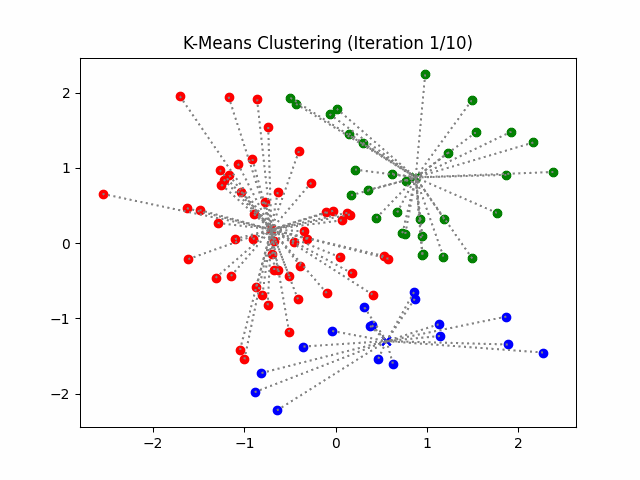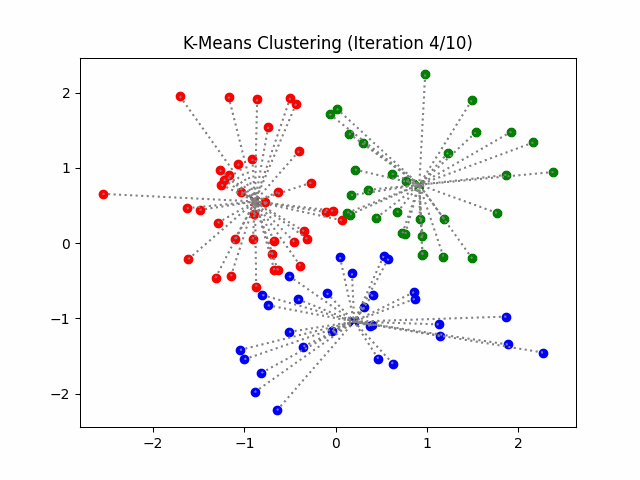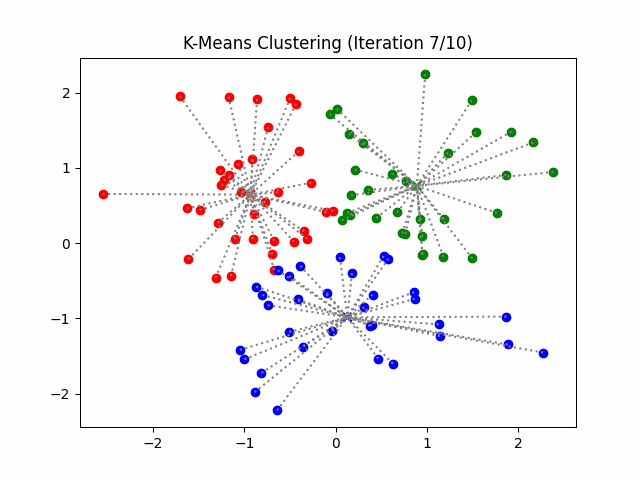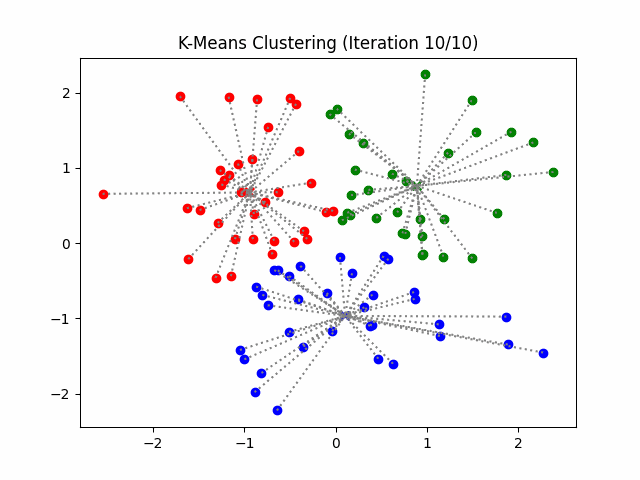
- K-means
- Mixture of Gaussians
- Spectral Clustering
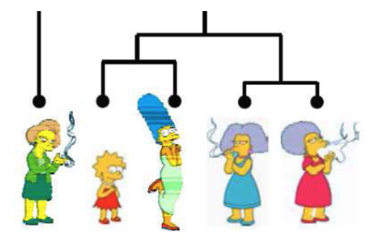

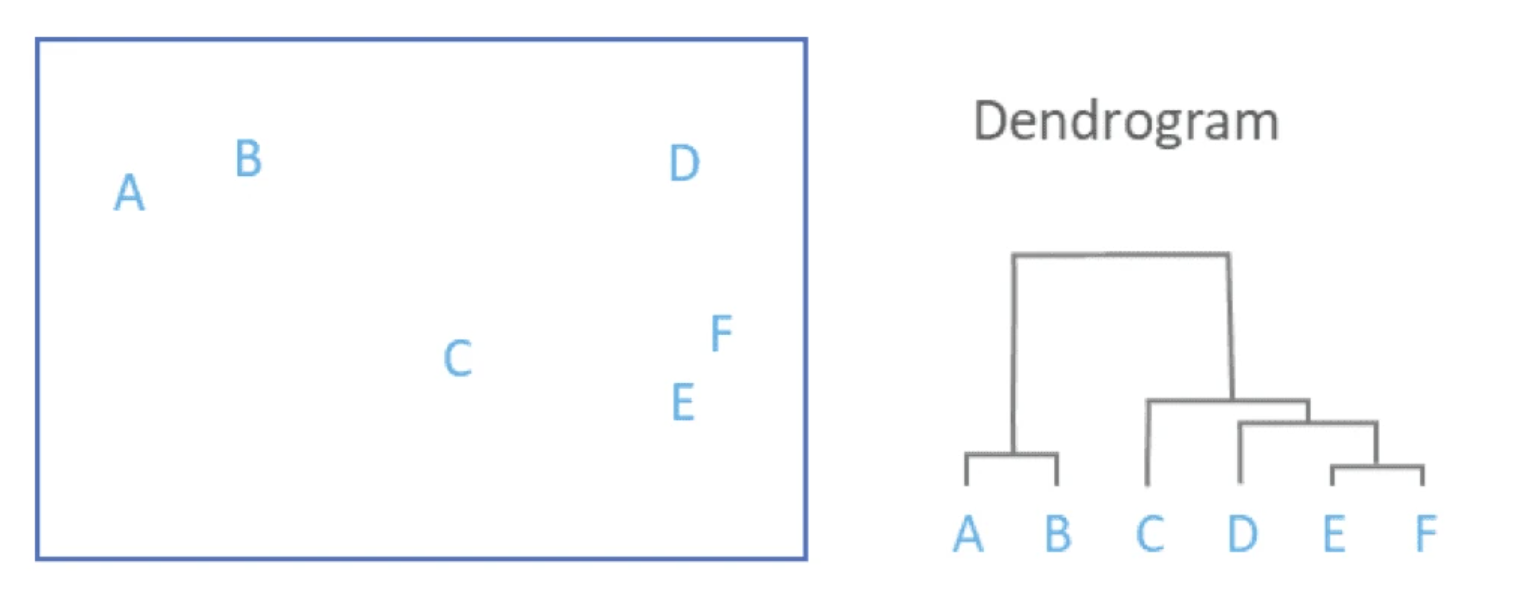
Hierarchical Clustering Example
Clustering Examples: Image Segmentation
Goal: Break up the image into meaningful or perceptually similar regions

K-Means Visualization
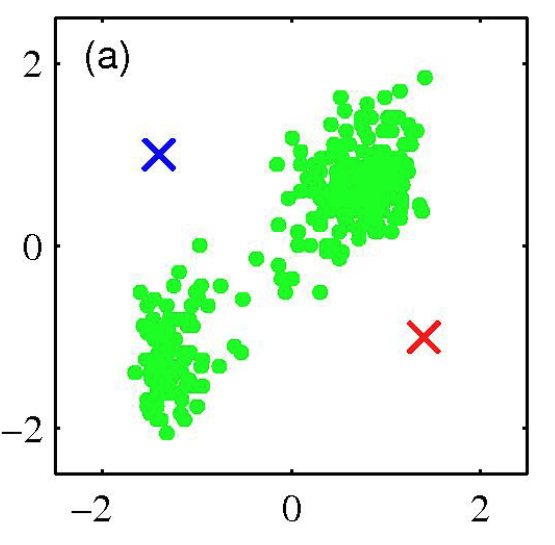
K-Means Example: Step 1
Initial random centers (K=2)
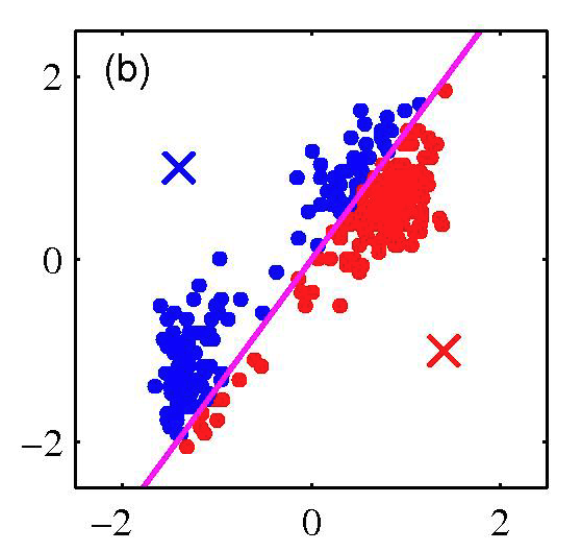
K-Means Example: Step 2
Assign points to nearest center
K-Means Example: Step 3
Repeat until convergence
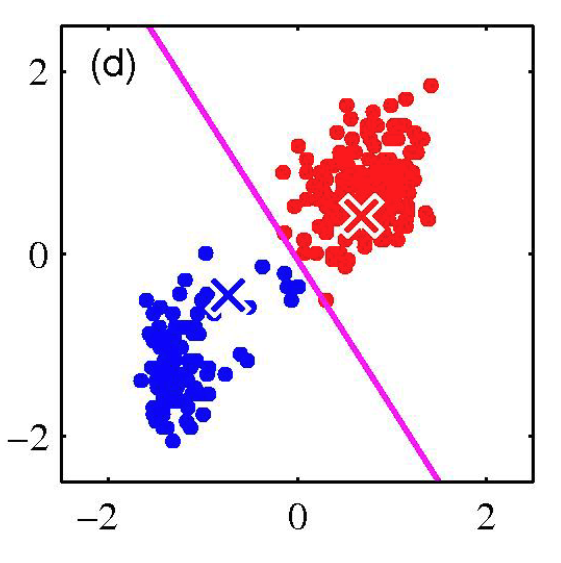
K-Means Example: Step 4
Change the cluster center to the average of the assigned points
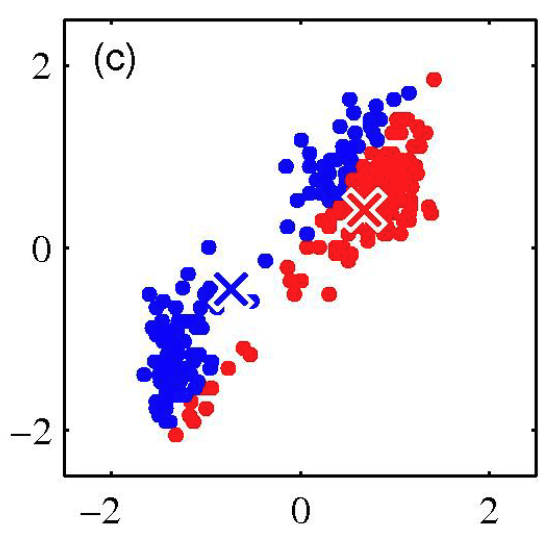
K-Means Getting Stuck

Example of cases where K-Means gets stuck
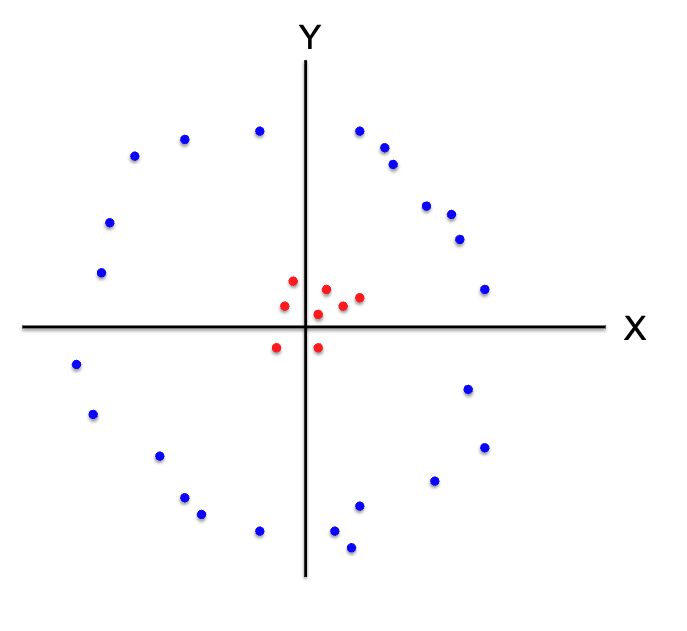
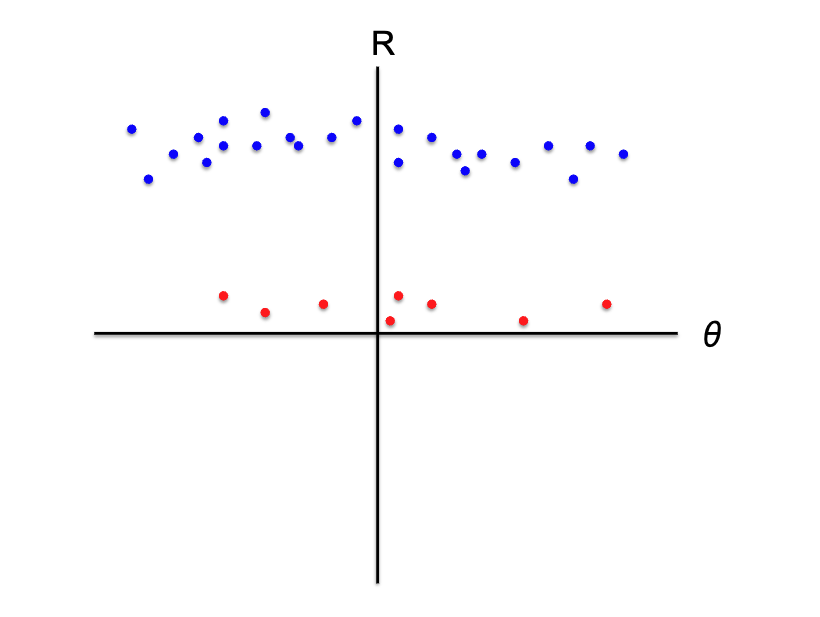
How we can handle such cases
Final Segmented Image
